Unter Diskretisierung versteht man die Gewinnung algebraischer (diskreter) Daten aus kontinuierlicher Information.
In vielen praktisch bedeutsamen Situationen muß rechner-externe kontinuierliche Information über das zu modellierende Objekt oder Phänomen (elektrische Spannungen, optische oder akustische Information etc.) verarbeitet werden. Die Verbindung zu den am Computer implementierten Programmen (Approximationsalgorithmen etc.) erfolgt durch geeignete Hard- und Software zur Informationsgewinnung: Meßgeräte, Sensoren, Analog-Digital-Wandler etc., die in Vorverarbeitungsschritten diskrete (algebraische) Daten produzieren, die am Computer gespeichert und verarbeitet werden können.
Dabei gibt es aber ein Problem: Es ist fast unvermeidbar, daß durch die Diskretisierung Information verlorengeht:
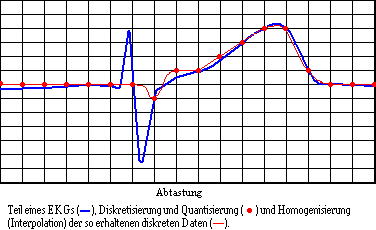
Beispiel (Medizinische Daten): Basis einer automatischen Analyse von Elektrokardiogrammen (EKG) ist z.B. die Messung der Potentialunterschiede zwischen verschiedenen Ableitstellen im elektrischen Feld des Herzens. Die analogen Meßsignale U1(t), U2(t), ... Uk(t) sind elektrische Spannungen (als Funktionen der Zeit), die durch Analog-Digital-Wandler diskretisiert und quantisiert werden müssen. Es kommen hierfür nur Punkte eines Rasters in Frage. In der nachfolgender Abbildung ist deutlich zu sehen, daß zwei "Peaks", die zwischen den Abtaststellen liegen durch die Diskretisierung verlorengehen:
Auf diese Art verlorengegangene Information kann durch keine algorithmischen "Tricks" wiederbeschaffen werden. Information, die in den diskreten Datenpunkten nicht mehr enthalten ist, kann günstigstenfalls durch zsätzliche Daten (z.B. Ableitungsschranken) grob quantifiziert werden.
Bei der nichtadaptiven Diskretisierung werden k "Informationsstücke" über die zu approximierende Funktion f,
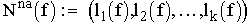
in voneinander unabhängigen Informationsoperationen gewonnen, deren Anzahl a priori festgelegt ist. Die Ermittlung nichtadaptiver Information kann also sehr effizient auf Parallelrechnern durchgeführt werden:
| Ermittlung von l1(f) | -> | Prozessor 1 |
| Ermittlung von l2(f) | -> | Prozessor 2 |
| ... | ... | |
| Ermittlung von lk(f) | -> | Prozessor k. |
Nichtadaptive Information wird dementsprechend auch Parallel-Information genannt. Die Gesamtzeit zur Ermittlung von Nna(f) ist durch die längste Zeit gegeben, die von einem der k eingesetzten Prozessoren benötigt wird.
Bei der adaptiven (dynamischen) Diskretisierung hägt zu jedem Zeitpunkt der weitere Verlauf des Abtastprozesses von der bereits verfügbaren Information ab. Dabei wird Information über f sukzessive gewonnen:
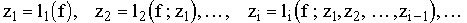
Dabei hängt zi, der i-te (skalare oder vektorielle) Wert der Informationsoperation, von den schon vorher erhaltenen Werten z1, ... , zi-1 ab:
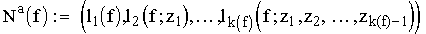
Eine parallele Auswertung der Informationsoperationen kommt daher in diesem Fall nicht in Frage - adaptive
Information muß squentiell ermittelt werden. Sie wird daher auch sequentielle Information genannt.
Die Anzahl k(f) der Datenpunkte wird dynamisch, also im Verlauf des Rechenvorganges, bestimmt: Nach der Ermittlung
jedes Wertes zi wird ein Abbruchkriterium stopi(z1, z2, ... , zi)
überprüft, das - auf der Basis der gesamten bis dahin verfügbaren Information - entweder zur Entscheidung
"Weiterrechnen" oder zum "Abbrechen" führt. Nach dem Abbruch beim i-ten Schritt bildet
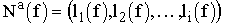
die dann adaptiv gewonnene Information über f.
Beispiel (Bisektion) Eine Nullstelle einer stetigen Funktion f : [0,1] -> R, deren Funktionswerte f(0) und f(1) verschiedenes Vorzeichen besitzen, kann mit Hilfe adaptiv gewonnener Information über f numerisch berechnet werden. Man berechnet zunächst f(0.5). Dann ist entweder f(0.5) = 0, oder eines der beiden Intervalle [0,0.5] und [0.5,1] hat wieder Funktionswerte am Rand, deren Vorzeichen verschieden sind. Der Mittelpunkt xm dieses Intervalls ist die nächste Stelle, an der f ausgewertet wird, usw. Die Information (f(0), f(1), f(0.5), ...) ist offensichtlich adaptiv, da es unmöglich ist, zu sagen, wo die nächste Funktionsauswertung vorzunehmen ist, wenn man die vorhergehende Funktionsauswertung nicht kennt. Eine Parallelisierung des Bisektionsverfahrens ist daher unmöglich.
Bei der Diskretisierung kontinuierlicher Information unterscheidet man zwei Methoden:
Am besten läßt sich dies an einem Beispiel verdeutlichen:
Beispiel (Bildverarbeitung): Ein Bild ist eine Intensitätsfunktion
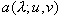 , die für die Punkte
, die für die Punkte
 die Intensität
("Helligkeit") der elektromagnetischen Schwingung mit der Wellenläge ("Farbe")
die Intensität
("Helligkeit") der elektromagnetischen Schwingung mit der Wellenläge ("Farbe")
![$\lambda \in [\lambda_{\min},\lambda_{\max}]$](pic/f02_0108.gif) angibt.
Für die Verarbeitung am Computer muß jedes Bild diskretisiert werden.
angibt.
Für die Verarbeitung am Computer muß jedes Bild diskretisiert werden.
Die Ortsdiskretisierung erfolgt üblicherweise auf quadratischen Rastern mit 2n x 2n Punkten, sodaß sich als Resultat eine quadratische Bildmatrix ergibt. Die Bildmatrizen haben in vielen Fällen die Dimension 512 x 512, 1024 x 1024, oder 2048 x 2048 (n= 9, 10 oder 11).
Die Amplitudendiskretisierung (Quantisierung) wird im allgemeinen so vorgenommen, daß 1 Byte (8 Bit) zur Kodierung ausreicht. Die Wellenlänge kann z.B. durch die Zerlegung in drei Spektralbereiche - Rot, Grün- und Blaubereich - und die Verwendung von drei entsprechenden Bildmatrizen berücksichtiget werden (RGB-Codierung).